Database System
Last Modified: 4/10/2025
1 SQL Part Ⅰ
1.1 SQL Introduction
2 Disks & Drives
2.1 DBMS Architectures
Features
- Organized in layers
- Each layer abstracts the layer below: Manage complexity (easy to use) & Performance assumptions (assume the perfomrance of lower layers)
- Two cross-cutting issues related to storage and memory management: Concurrency control & Recovery
2.2 Storage Techniques
Memory Hierarchy
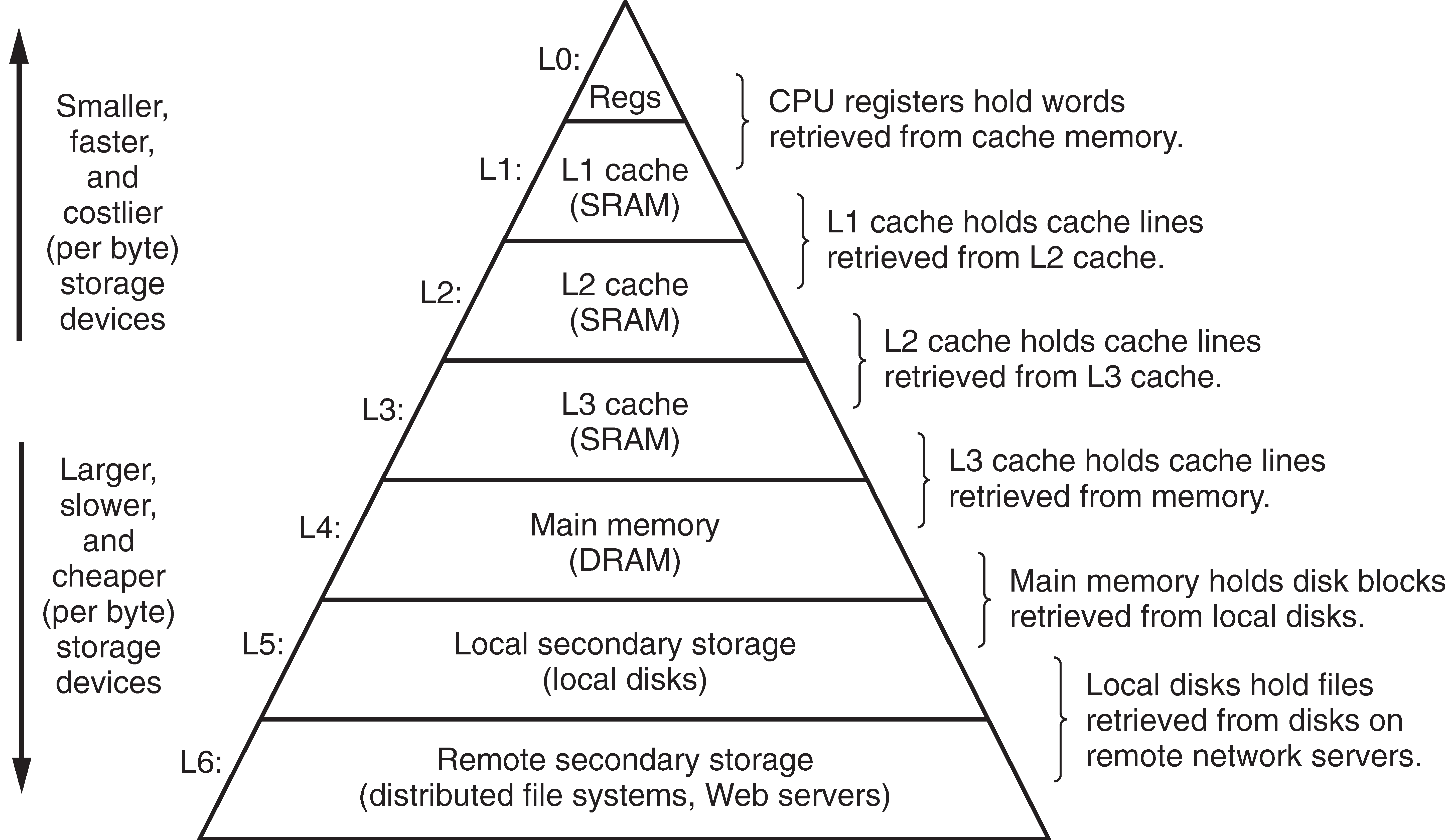
2.2.1 Disks
Disk Components
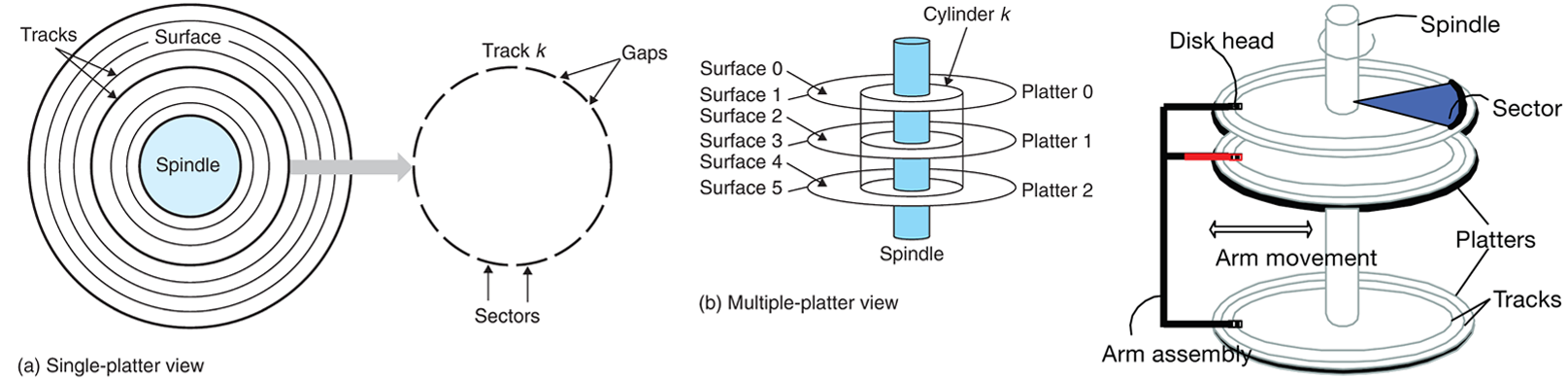
Platters spin together (around 15000 rpm). Arm assembly can move in or out to position a head on a desired track, but only one head reads/writes at any one time.
Disk Operation & Access Time
Disks read and write data in sector-size blocks with access time of three components.
Seek Time:
Moving arms to position disk head on track that contains that contains the target sector.Rotational Delay:
Waiting for block to rotate the first bit of the target sector to pass under the head.Transfer Time:
Moving data to/from disk surface (Read/Write the contents of the sector).
Disk Capacity
Disk capacity is determined by the following technology factors.
- Recording Density (bits/in): The number of bits that can be squeezed into a 1-inch segment of a track.
- Track density (tracks/in): The number of tracks that can be squeezed into a 1-inch segment of the radius extending from the center of the platter.
- Areal density (bits/in2): The product of the recording density and the track density.
2.2.2 Random Access Memory (RAM)
Random-access memory (RAM) is a form of electronic computer memory that can be read and changed in any order, typically used to store working data and machine code. A random-access memory device allows data items to be read or written in almost the same amount of time irrespective of the physical location of data inside the memory.
RAM is a type of volatile memory (a type of memory that requires power to maintain the stored information). There are two widely used forms of RAM: SRAM and DRAM (there are SDRAM and so forth as well).
| SRAM | DRAM | |
|---|---|---|
| Composition | Typically 4 or 6 transistors | 1 transitor + 1 capacitor |
| Basic Structure |  | 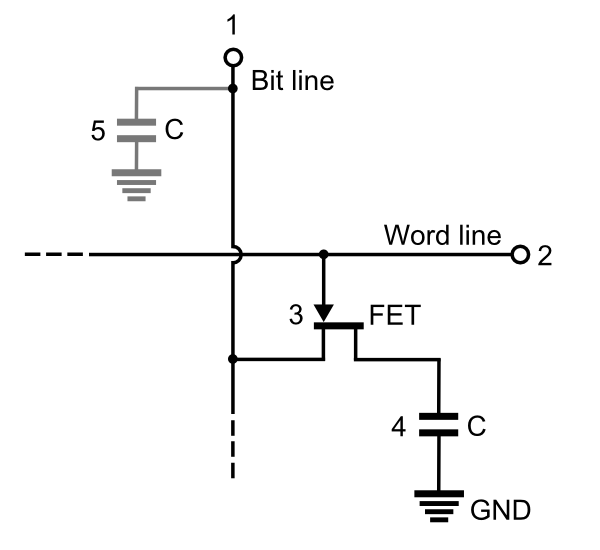 |
| Relative Access Time | ||
| Refreshing | Does not require refreshing, loses data if power is turned off | Requires constant refreshing to maintain data, loses data if not refreshed |
| Applications | Cache memories | Main memories, frame buffer |
2.2.3 Solid State Disks (SSDs)
Key Terminology
- Cells: The fundamental units of storage, storing a single bit of information.
- Pages: Groups of cells form pages. These are the smallest units that can be read or written to. Typical page sizes are 4KB or 8KB.
- Blocks: Groups of pages form blocks. Blocks are the smallest units that can be erased. Typical block sizes are 1-2MB.
- Planes/Dies/Channels: These are ways to parallelize read/write access.
For reading in SSDs, the process is straightforward:
- Address Mapping: The SSD controller translates logical block addresses (LBAs) to physical block addresses (PBAs).
- Read: The SSD controller reads the data from the physical block address.
For writing in SSDs, the process is more complex:
- Address Mapping: Same as in the reading procedure.
- Check Page State: Check if the page to be written already contains data. If the
page is part of a block that has been recently erased (all ‘1’s), SSD can directly
write to the page. Otherwise, the SSD must:
- Read block contents, identify & copy valid pages (not the target page we want to modify) to a new, erased block (write amplification).
- SSD controller uses the new modified data and writes the new content to the corresponding page in the new block, updates the mapping table, and the original block is ready for garbage collection.
2.2.4 Locality
Principle of Locality
- Temporal Locality: Memory location that is referenced once is likely to be referenced again multiple times in the near future.
- Spatial Locality: If a memory location is referenced once, then the program is likely to reference a nearby memory location in the near future.
#include <iostream>#include <vector>
int main() { std::vector<int> data(1000, 1); int sum = 0;
// Temporal locality: 'sum' is accessed repeatedly in the loop for (int i = 0; i < data.size(); ++i) { sum += data[i]; // Spatial locality: 'data[i]' is accessed sequentially }
std::cout << "Sum: " << sum << std::endl; return 0;}/* TODO: Add more examples */
2.3 Database Files
For database system, tables are stored as logical files on disk. Each file contains a collection of pages, and each page contains a collection of records. Normally, a record represents a row (tuple) in a table, and it contains a collection of fields (attributes).
API for higher levels of DBMS
- Insert/delete/modify record
- Fetch a particular record by record id, a record id is a pointer encoding pair of pageID & location on page
- Scan all records
Pages are managed by:
- Disk space manager (on disk): Pages read/written to physical disk/files.
- Buffer manager (in memory): Higher levels of DBMS only operate in memory.
Procedure
- The DBMS wants to access a specific record. It determines the logical page number containing that record, and asks the buffer manager for the page with that logical page number.
- Buffer Hit/Miss:
- Hit: If the page is already in the buffer pool, the buffer manager returns a pointer to that page in memory.
- Miss: If the page is not in the buffer pool:
- The buffer manager chooses a victim page to replace.
- If the victim page was dirty (modified), the buffer manager asks the disk manager to write it back to disk.
- The buffer manager asks the disk manager to read the requested page from disk and load it into a frame in the buffer pool.
- The buffer manager returns a pointer to the newly loaded page in memory to the DBMS.
For DBMS, several of the possible ways of organizing records in files are:
- Unordered Heap Files: Records placed arbitrarily across pages.
- Clustered Heap Files: Records and pages are grouped.
- Sorted Files: Pages and records are in order.
- Index Files: May contain records or point to records in other files (e.g., B+ trees, linear hashing).
2.3.1 Heap Files
Unordered heap files: Collection of records in no particular order.
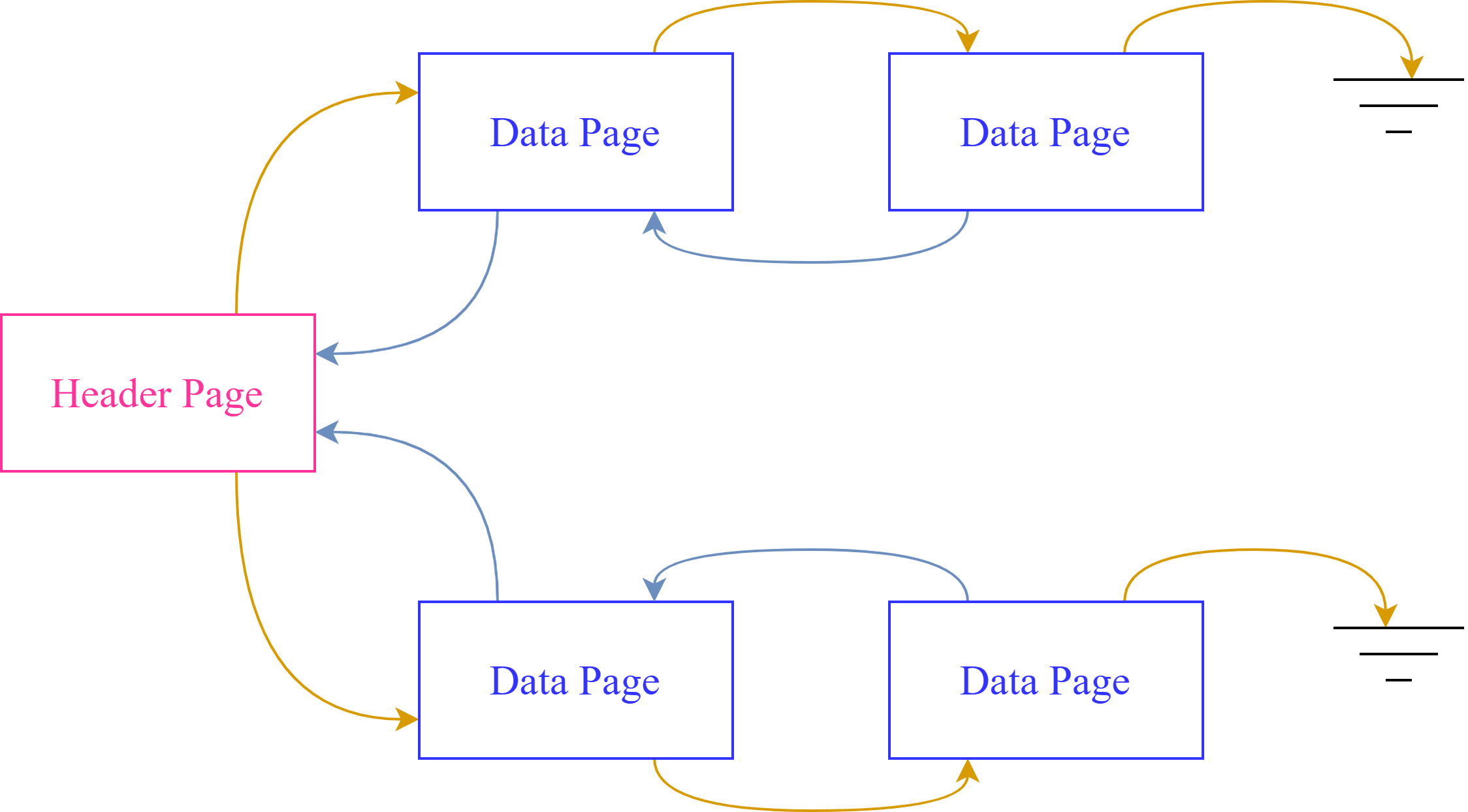
- Implement heap files as a list: difficult to find a record.
- Implement heap files as a page directory:
- Directory ectries include number of free bytes on the referenced page.
- Finding a page to fit the record required far fewer page loads than the linked list.